- Published on
Análisis de Redes sociales para alcalde de Guayaquil 2019
- Authors

- Name
- Gustavo Cevallos
- @wgcv
Hace mucho que no escribo, pero realmente fue una combinación de falta de tiempo y falta de noticias controversiales políticas, y que sean de mi interés.
El día del cierre de campaña vamos a analizar el movimiento y el impacto de los candidatos para el período 2019 de alcalde de la ciudad de Guayaquil, agregando un poco de Inteligencia Artificial para analizar qué hablan las personas sobre ellos. Pero primero conozcamos a los 17 candidatos a la alcaldía, que por cierto nunca habíamos tenido tantos para una elección seccional.
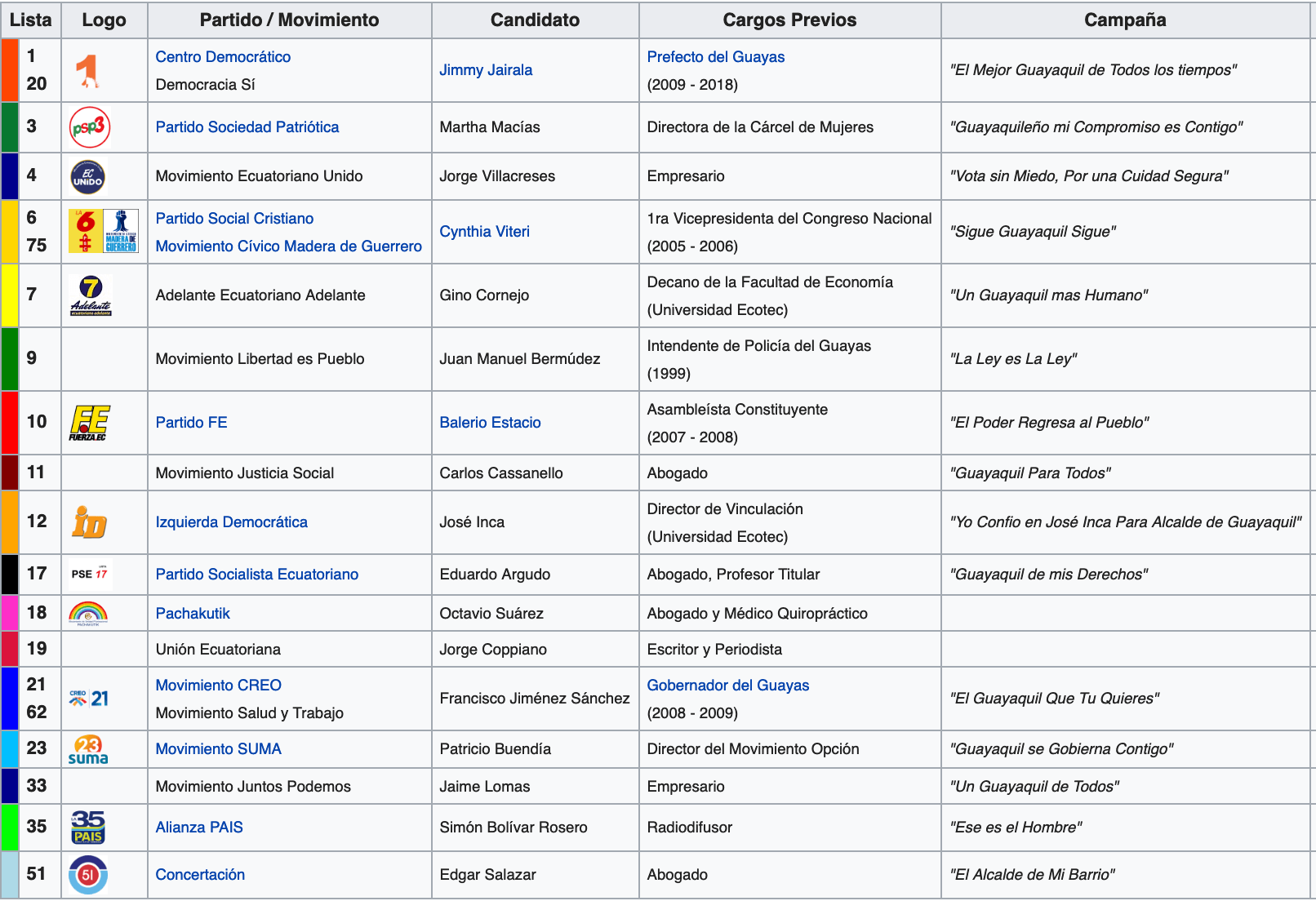
De los 17, solo de 14 encontré una cuenta en Twitter de los cuales: Jorge Copiano, Octavio Sùarez, Carlos Cassanello, alguien debería decirles que existen las redes sociales o deberían crear un username que tenga relación con su nombre y se los pueda encontrar. Adicionalmente a los 17 participantes decidí ver quien más merecía entrar en este análisis, para lo cual el primero que busqué fue a “Sarmiento Es Pueblo”, pero al parecer solo se limita a poner su nombre en las propagandas políticas y dejó de usar redes sociales luego de apoyar a la “Revolución Ciudadana”. Después decidí agregar al siguiente sujeto que hace campañas pero no es candidato a nada, a Jaime Nebot, y la razón fue porque #YOLO. Mentira, creo que es importante analizarlo para entender la posición de su partido, es el actual alcalde y por cierto terminaremos descubriendo en este post porque acompaña tanto y hace tanta campaña con sus candidatos de Madera de Guerreros.

Sarmiento es Pueblo es la sensación de cada fiesta electoral porque baila con el feo, con la rata y con el guapo.
Dataset
El dataset es la colección de datos, para este análisis de todos los tweets que mencionan a las cuentas de los candidatos y al invitado especial. La recolección empezó el jueves 14 de marzo y terminó en la madrugada del 21 de marzo (Casi continua, algún momento de toda la semana dejó de capturar por un par de horas).
Pd. ¡Si no eres desarrollador de software no tengas miedo, que si podrás entenderlo!
Veamos que columnas fueron capturados:
Columnas
print(df.columns) Index(['ID', 'creado_en', 'nombreusuario', 'nombre', 'creacion_usuario', 'seguidores', 'siguiendo', 'numero_tweets', 'geolocalziacion_habilitada', 'idioma', 'origen', 'idioma_del_tweet', 'tweet', 'hashtags', 'es_respuesta', 'jimmyjairala', 'cedeno_marth', 'jorgevillacrese', 'CynthiaViteri6', 'GinoCornejoM', 'BermudezBronson', 'balerioestacio', 'inca_jose', 'EduardoArgudoG', 'fcojimenez21', 'patobuendia23', 'jaimelomas74', 'Simon_BolivarEC', 'edgarsalazar_51', 'jaimenebotsaadi'], dtype='object')
Cantidad de registros El primer valor es la cantidad de registros o filas y la segunda la
cantidad de columnas print(df.shape) (11230, 30)
Analicemos nuestro Dataset ### Tweets vs Retweets Vamos a ver cuantos son tweets únicos y cuantos
son retweets:
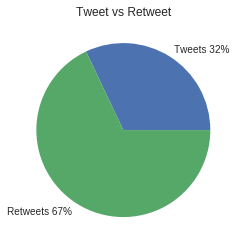
Se ve claramente que existe más interacción en compartir un contenido que postear un contenido. Pero a mi parecer (solo por análisis visual) existen muchas cuentas sospechosas que les dan RT únicamente a ciertos candidatos con muy pocos seguidores o hasta sin foto de perfil, pero bueno cada cual tiene derecho de tener su cuenta como quiera y hay que recordar esta red social es el nido del odio.
Menciones
Veamos quien es el más famoso en las redes, a quien le pasan escribiendo y etiquetando (Por cierto adivinan quien esta en 4to lugar?)
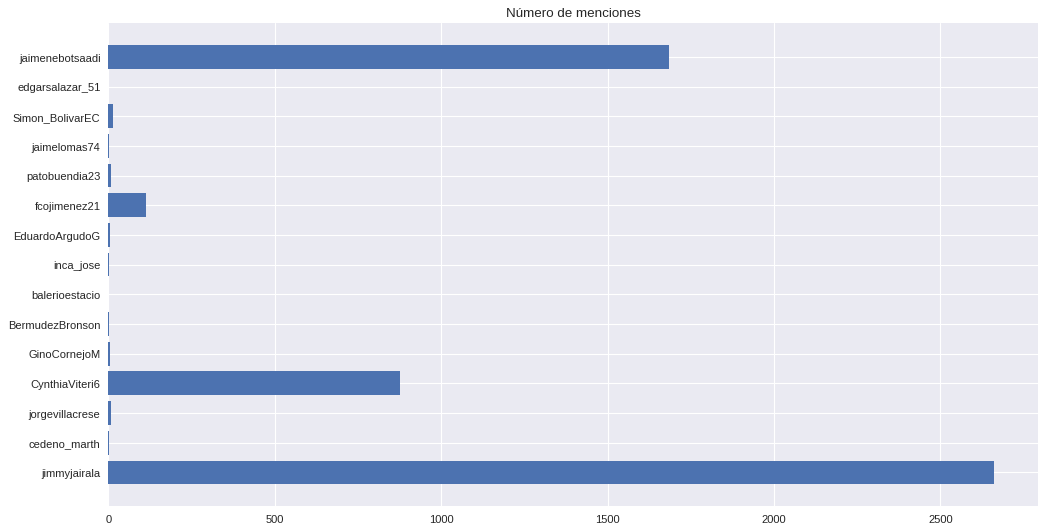

Felicidades Jimmy, tenemos un ganador!
Definitivamente Jimmy se lleva a todos y por bastante, al parecer es el más hablado en las redes sociales y mencionado. Lo cual no me sorprende, viene haciendo campaña en redes sociales desde las elecciones a presidente donde ofrecía presentaba a sus hijos como si el streaming de facebook live fuera TVentas.
Al parecer Nebot opaca un poco a su candidata Cynthia, pero tiene sentido mucho de sus menciones son para denunciar problemas que se ven actualmente en la ciudad de Guayaquil. Al resto creo que deberían pensar conseguir un mejor Community Mananger o pedir ayudar al troll center de Bélgica.
Al candidato que no quiero mencionar que dijo “Estas elecciones hay candidatos que visitan a la gente y candidatos solo redes sociales” parece que hasta en eso está equivocado o hablaba de él. Luego de ver el impacto de los 17 candidatos, vamos a analizar solo los que tiene un número considerado de interacción, a la final ¿Quien recuerda más de 5 candidatos de la lista inicial?
Seguidores de los que interactuan
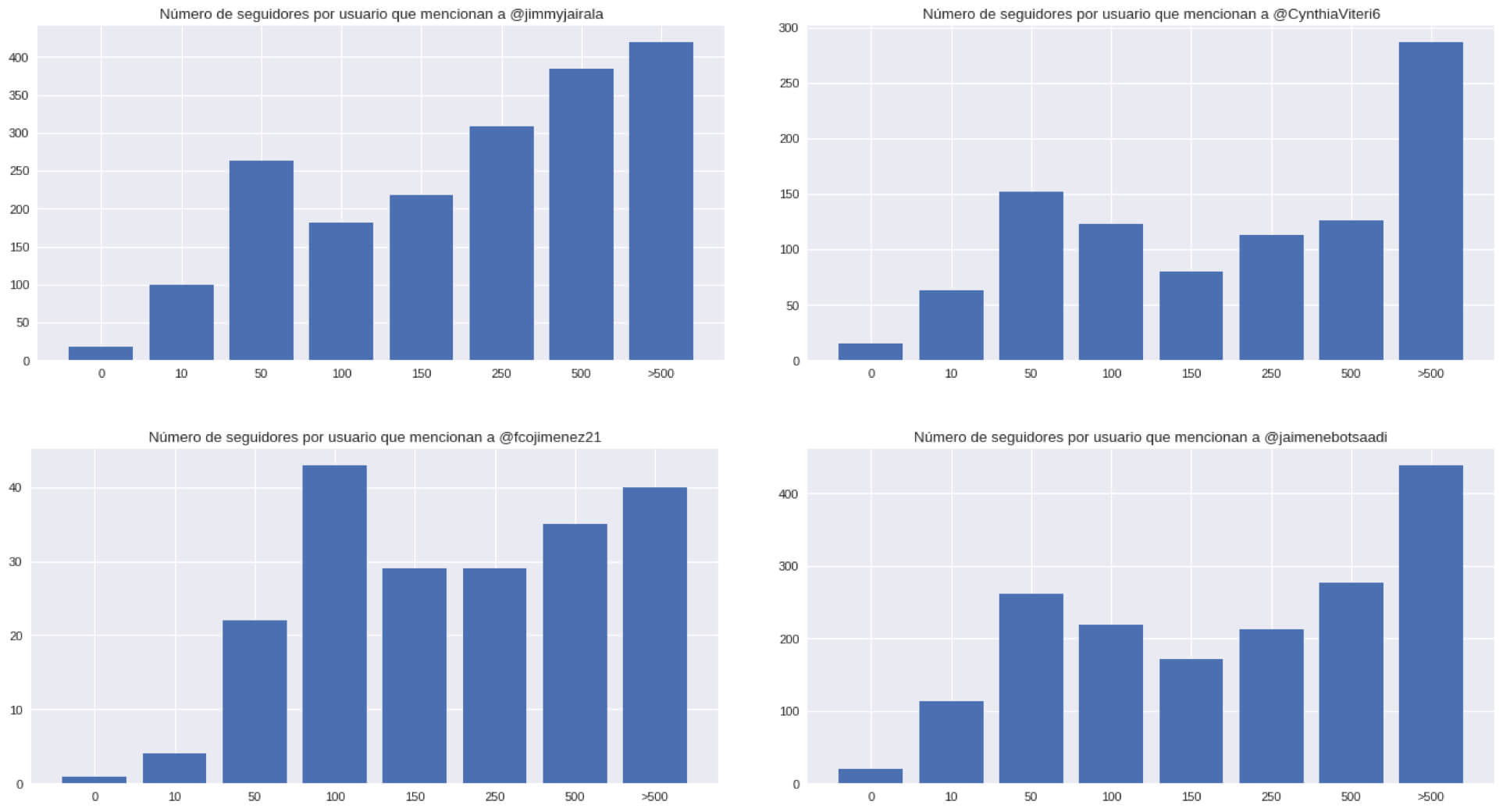
Después del gobierno de los trolls centers, pensamos que todo político tiene uno. Este análisis no dirá que, si los tiene o no los tienen, pero vamos a dejar unos gráficos para que el lector pueda interpretarlos y concluir.
Gráfico de los seguidores por cada usuario que interactuó
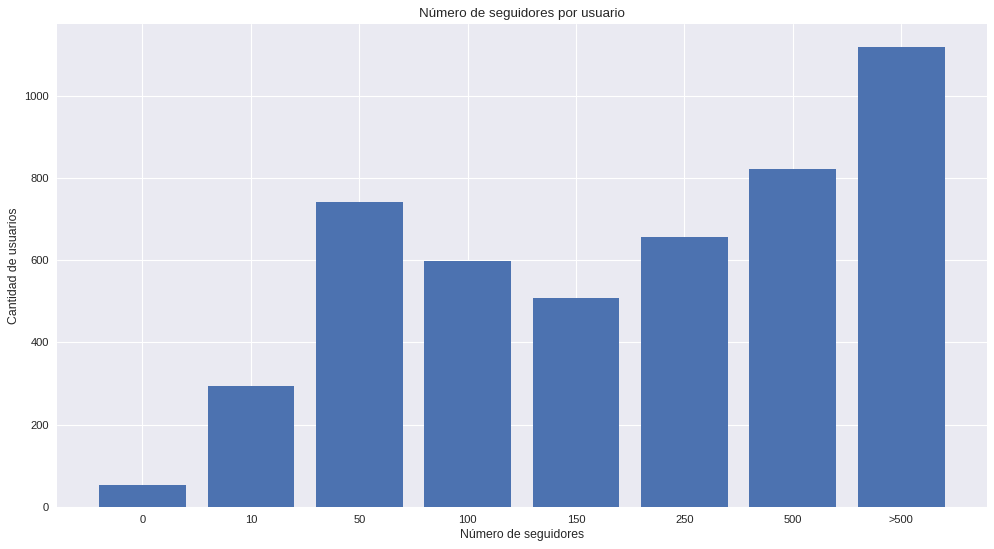
Gráfico de los seguidores por cada usuario que interactuo por candidatos
Hora que interactuan los usuarios
Ni yo lo pude creer, la cantidad de personas que pasa en redes sociales en las noches. Al parecer antes de dormir es costumbre enviar tu tweet de apoyo o de odio a tu próximo alcalde.
Pd. Si te toca mesa espero que duermas temprano el día anterior, si no tendrás una multa de $59.10 más $47.40 si no votaste.
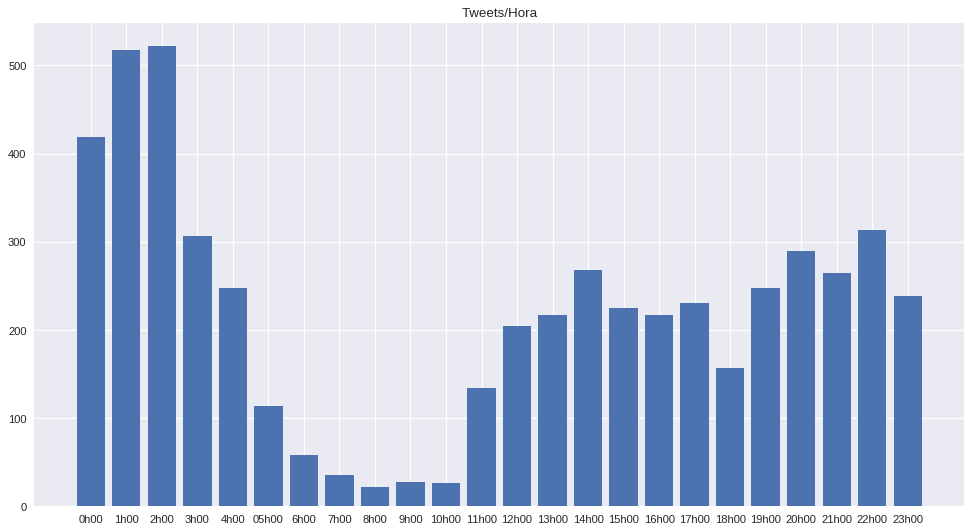
Gráfico hora de los tweets por candidatos
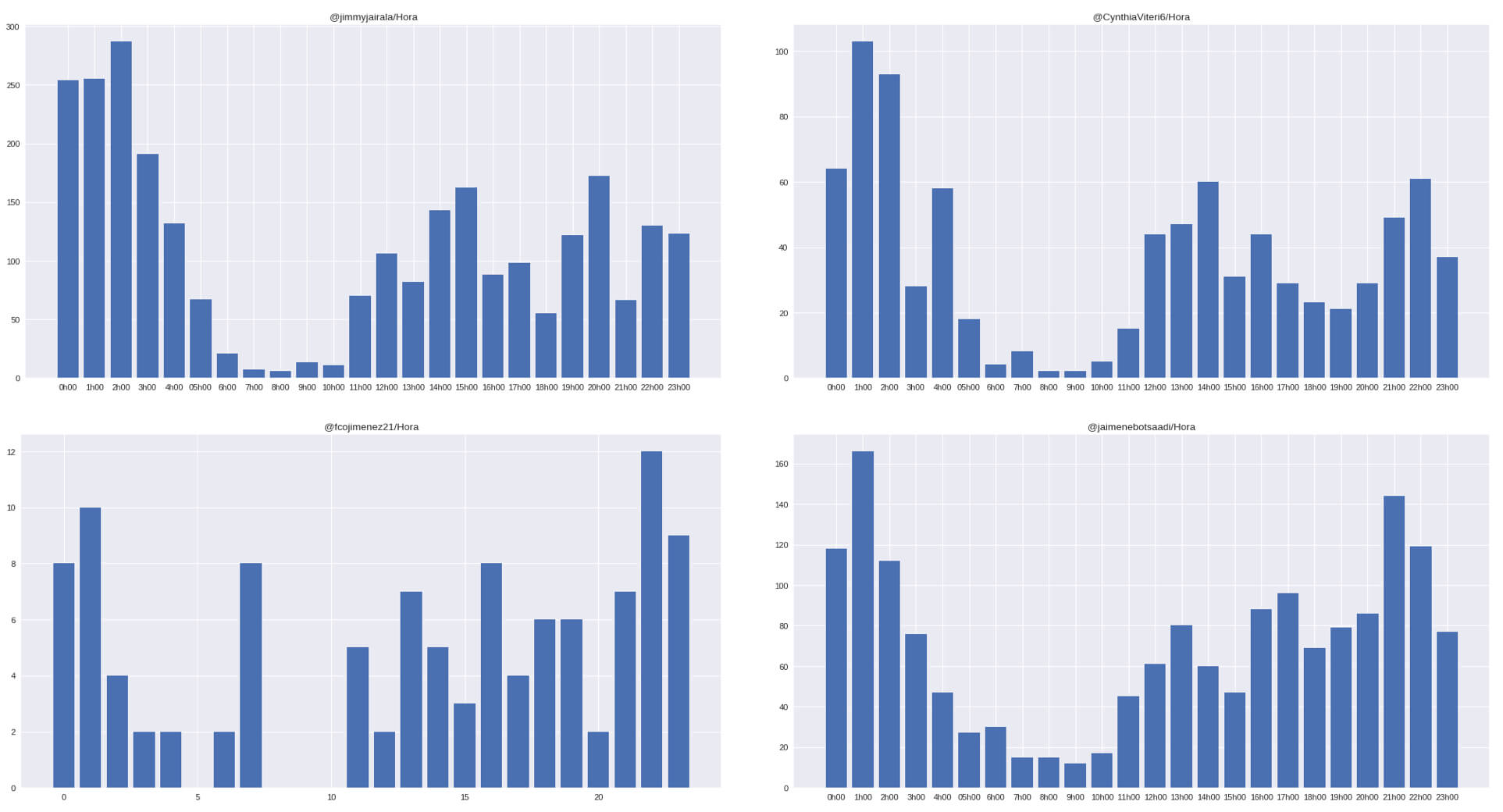
¿O todos contrataron troll center nocturno para abaratar costos o Guayaquil se mueve de noche, realmente quien quiere echar odio o apoyar con el calor que hace las 12 del día? Mejor cuando ya estas cómodo en tu cuarto. (A criterio personal, como dije en la parte superior creo que si existe un boost social media engagement en cuanto a Retweets, me imagino que a esta hora los ponen a funcionar para disimularlo al día siguiente).
Por cierto, Cynthia, deja de llegar a casa a las 20h00 y desconectarte de la política, quizás por eso no tienes interacciones, Guayaquil recién empieza a expresarse a esa hora.
Analicemos los sentimientos
¡¿Como que analicemos los sentimientos?! ¿Acaso vamos a poner al loco del ático a clasificar si es positivo o negativo cada tweet?
Como es normal en mi blog combinar política, fuego y tecnología y a veces hasta otros temas, vamos a analizar los sentimientos de cada uno de los tweets mediante inteligencia artificial para lo cual explicaré un poco en este post. (Si solo quieres ver números baja hasta ver el gráfico, porque hablare mucho de AI).
La inteligencia artificial tiene diferentes ramas, más ramas y sub-ramas, pero las dos principales podríamos decir que son Machine Learning y DeepLearning (de lo cual Deeplearning realmente es una sub-rama de Machine learning). El DeepLearning es la forma de crear AI con redes neuronales, la cual trata de simular al cerebro humano (Básicamente son matrices multiplicando matrices, usando funciones de activación y conectando a otras matrices con funciones de activación). Si quieres leer más sobre Inteligencia Artificial.
Dentro de las redes neuronales, podemos encontrar las RNN (Recurrent Neural Network) y dentro de las RRN encontramos las LSTMs (Long Short Term Memory networks ) para descubrí que no tiene traducción así que dejaré la mía LSTMs (Red de Memoria de Corto plazo), esta clase de red es excelente para operaciones que tienen que tener un historial en el tiempo como el trading y porque no el lenguaje, porque cada palabra va conectada con otra y cambia el significado si unimos diferente palabras.
Para poder clasificar los tweets en positivo y negativo, primero vamos a crear una red LSTMs que pueda entender el idioma español, lo cual llevaría algunas horas (o días, dependiendo el presupuesto para la GPu) entrenándola, así que usare model-eswiki-30k (Siempre es mejor usar algo que alguien más entrenó antes de entrenar algo ustedes, así ganan la experiencia anterior), este modelo está basado en WikiText-103 de Saleforce pero para el idioma español (Si se preguntan es pyTorch pero hay forma de exportarlo TF).
Un momento, wikipedia es una enciclopedia y tiene un lenguaje muy formal, ¿Como es posible que entienda el lenguaje de los guayaquileños? Definitivamente no va a ser muy preciso, así que vamos a entrenar con nuestros tweets dicho modelo y mejorar la predicción de la siguientes N palabras. Con una sola entrenada obtenemos un accuracy bastante alto de 0.314 (Claro alto para lo que estamos midiendo, la siguiente palabra de una oración)
epoch train_loss valid_loss accuracy time 0 5.099202 3.970043 0.314598 00:14
Algunos entrenamientos más, estoy más satifecho con el accuracy, al parecer escribir un tweet es bastante sencillo. ✌🏻
Total time: 03:03 epoch train_loss valid_loss accuracy time 0 3.937126 3.578753 0.354821 00:18 1 3.579814 3.021521 0.446741 00:18 2 3.168866 2.618203 0.509643 00:18 3 2.799575 2.372685 0.555268 00:18 4 2.515592 2.227562 0.578438 00:18 5 2.303267 2.134162 0.594196 00:18 6 2.143560 2.081303 0.602679 00:18 7 2.019376 2.051470 0.607232 00:18 8 1.956064 2.042516 0.609821 00:18 9 1.929175 2.042511 0.609688 00:18
Entonces ¿Qué hace mi modelo?
El modelo actual predice la siguiente palabra, esto me servirá para poder entender el contexto de toda la oración y no cada palabra.
Esto significa puedo darle unas cuantas palabras para que escriba algo (Si literal, el modelo escribe)
TEXT = "La ciudad de Guayaquil" N_WORDS = 20 N_SENTENCES = 2 print("\n".join(learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)))
Como los candidatos son para la Ciudad de Guayaquil, empecemos nuestra oración "La ciudad de Guayaquil" y vemos que genera nuestro modelo (Creo que nunca veremos trabajar dos políticos de la mano pero mi modelo sí):
La ciudad de Guayaquil también se viste de naranja y sueña con # elmejorguayaquildetodoslostiempos con @jimmyjairala y el equipo de @la6mdg xxbos RT La ciudad de Guayaquil se salvó del Socialismo de SXXI . Fue el bastión que nunca se pudieron tomar .
Clasificación
Una vez entrenado mi modelo que entiende como las personas habla de política vamos a crear un clasificador, para que me digan si es el tweet es bueno o malo. Para esto me tocó a mí y la comunidad de AI Saturdays leer y clasificar los tweets si eran positivos o negativos, luego de eso entrenar el modelo.
Con un accuracy final de 0.85% (Utilizando una relación de 80% entrenamiento 20% prueba). Esto quiere decir de cada 10 tweets, 1 tweet y medio podría estar mal clasificado, seguramente el tweet es bastante ambiguo.
epoch train_loss valid_loss accuracy time 0 0.355888 0.449902 0.834437 00:03 1 0.337926 0.415722 0.854305 00:03
En serio, puedes saber si mi tweet es positivo o negativo!?
Algunos ejemplos clasificados por el modelo:
learn.predict("Vamos a ganar mi alcalde") (Category P, tensor(1), tensor([0.0649, 0.9351])) learn.predict("Los mismos ladrones de siempre") (Category N, tensor(0), tensor([0.7378, 0.2622])) learn.predict("🐭🐭") (Category N, tensor(0), tensor([0.6929, 0.3071])) learn.predict("Es hora de un cambio") (Category P, tensor(1), tensor([0.4567, 0.5433])) learn.predict("Sinico, ladrón") (Category N, tensor(0), tensor([0.7175, 0.2825])) learn.predict("Tenemos el optimismo y convicción que el pueblo respaldará masivamente la propuesta de ") (Category P, tensor(1), tensor([0.0348, 0.9652])) learn.predict("no invierten nada . Porque si no les resulta el fraude y ganar las alcaldías que deseen en especial")[0] Category N
Una vez entrenado y con nuestro modelo funcionando, nos toca predecir cada tweet, tabularlos y ponerlos en un gráfico.
Tweets Positivos Vs Tweets Negativos
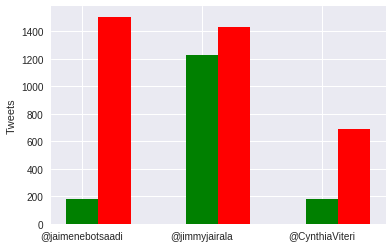
Se puede ver los dos candidatos principales tienen una mayor cantidad de tweets negativos que de positivos y que el títere la candidata de la lista de la alcaldía se lleva los comentarios negativos del periodo actual, mientras con Jimmy existe un desprecio y amor entre sus usuarios.
Lo interesante es ver como Jaime parece un tercer candidato, claro teniendo bastantes comentarios negativos mencionando problemas actuales de la ciudad o relaciones políticas con otros del gobierno, pero también se ve un apoyo para una candidatura de presidente la cual aún no es mencionada por él, pero si en sus usuarios apoyando dicha decisión.
Claro esta, que la realidad de las urnas no se miden en las redes sociales ni en internet. Para los niveles sociales altos se miden tomando un café y hablando de política que nunca llegará a un tweet, y en los estratos bajos por las camisetas que regalaron (No es literal, ni se habla de toda la población de segmento), esto me lo dejó claro en la última encuesta online de las elecciones presidenciales.
Recursos
Jupyter Notebook:https://colab.research.google.com/drive/17iqKSf5KRSSo3M7PsY74a7a6y4qjtZ1f
Dataset:https://drive.google.com/open?id=1-Ynl7kCl-k16KV2xvgqDum6SMU_TuO3q
https://drive.google.com/open?id=1hY1dIGnCcrvUxPZYlW4cu_6mEllYLJhZ-OsiqarMhe0
Gracias a Salvatierra, Jorge y la Comunidad Ai.